Abstract:
The proposed IRAM architecture is designed to reduce the processor-memory performance gap by including microprocessor and DRAM components on a single chip. The VIRAM architecture is an extension of IRAM which supports vector and DSP operations. We investigated the possibility of using the proposed vector IRAM (VIRAM) architecture for sophisticated DSP applications. In particular, we explored the use of low-delay codebook-excited linear prediction (LD-CELP) speech compression as a benchmark for VIRAM. We vectorized the most computationally intensive kernels of the LD-CELP algorithm using the proposed VIRAM vector assembly language. An implementation of LD-CELP including the vectorized components was run on the VIRAM simulator. We analyzed the performance of the vectorized functions using the VIRAM performance simulator and estimated the vectorization speedup relative to a scalar implementation to be 8.83 for the vectorized functions and 2.55 overall. Our results show that while the performance of LD-CELP can benefit substantially from a vector architecture, LD-CELP is a relatively challenging and heterogeneous DSP benchmark which demands a combination of vector and scalar performance.
As technological advances allow more powerful DSP systems to be
developed, there is interest in investigating the possibility of
applying vector architectures to DSP applications to improve
performance. The aim of our project is to implement a sophisticated
DSP benchmark using the VIRAM architecture, preferably an algorithm
which can take advantage of VIRAM's vector capabilities to maximize
efficiency. The VIRAM architecture is much more versatile and has more
powerful general-processing capabilities than a typical DSP chip. Thus
we believe that an ideal benchmark would be a relatively complex DSP
algorithm which retains many of the characteristics typical of DSP
applications. We selected low-delay codebook excited linear
prediction (LD-CELP) speech compression for several reasons: 1)
LD-CELP is a well-known algorithm with a well-defined international
standard; 2) the algorithm, while more complex than most commonly used
DSP benchmarks, contains a large proportion of repetitive array
calculations and multiply- accumulate computations; 3) like many DSP
applications, the LD-CELP algorithm is designed to meet strict
real-time performance requirements; 4) speech compression has a number
of potentially important practical applications for telecommunications
and portable computing systems; and 5) standard source code is readily
available. Several distinct CELP standards exist, most notably the 3.5
kbps U.S. Department of Defense CELP standard and the 16 kbps CCITT
LD-CELP standard. The LD-CELP standard trades off a lower compression
ratio for lower delay and a simpler algorithm; the available source
code is also cleaner and more amenable to analysis.
In this project, we are primarily interested in studying the
performance of LD-CELP on the VIRAM architecture. In particular, we
investigate how well LD-CELP vectorizes on VIRAM, which of VIRAM's
numerous vector-processing features are used by an efficient vector
implementation, and whether LD-CELP is a suitable DSP benchmark for
VIRAM. To answer these questions, we implemented LD-CELP on VIRAM and
analyzed the performance of our code using the available VIRAM
simulator tools. Our results lead us to explore the implications of
future hardware technologies for these applications which have
traditionally been dominated by specialized DSP systems.
This report is organized as follows: Section II contains a brief
overview of the LD-CELP algorithm. Sections III presents a general
analysis of the scalar code. Section IV describes our vector
implementation of LDCELP on VIRAM. Section V contains a detailed
performance analysis of our vectorized LDCELP system and a discussion
of the related issues. Section VI offers some concluding
remarks.
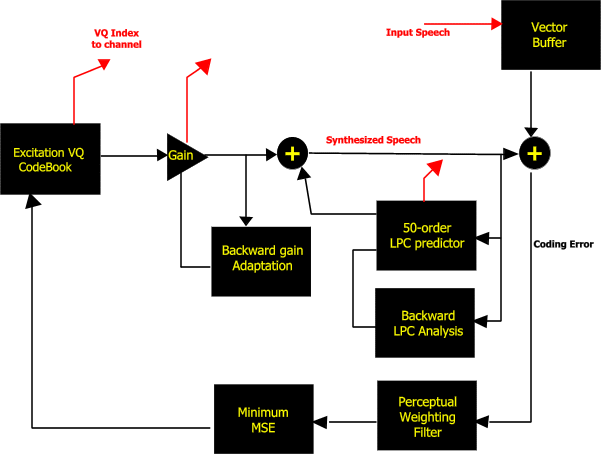
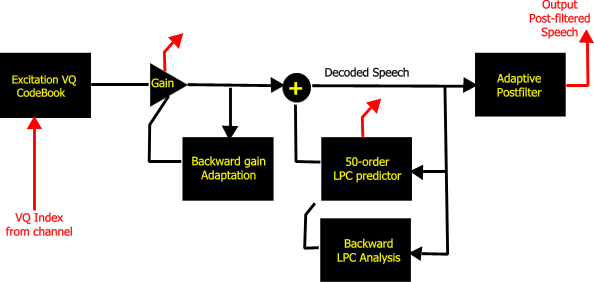
Figure 1 presents a block diagram of the LD-CELP encoder; Figure 2
presents a diagram of the decoder. Five consecutive speech samples are
buffered to form a vector. In the compressed form, each vector is
represented by a 10-bit codeword index. This vector is the basic unit
of data which is processed by the blocks in Figure 1.
Some of the important features of LD-CELP are presented as follows:
1. High Order Backward Adaptive LPC Predictor:
This is a 50th-order backward-adaptive predictor. Unlike
forward-adaptive predictors, which derive their predictor coefficients
from speech samples yet to be coded, backward-adaptive predictors
derive their coefficients from previously quantized speech samples. As
a result, backward-adaptive predictors do not need to buffer a large
frame of speech samples; this greatly reduces the encoding delay. (The
predictor is 50th-order in order to compensate for the difference in
quality associated with the lack of a pitch predictor similar to that
used in the original CELP algorithm.)
2. Perceptual Weighting FIlter:
This 10th-order weighting filter is used to maximize the subjective
quality of the generated speech.
3. Excitation Gain Adaptation:
Excitation gain is updated using a 10th-order backward-adaptive linear
predictor, based on previously quantized and scaled excitation
vectors.
4. Analysis By Synthesis Codebook Search for CELP:
The excitation signal for the speech is chosen by attempting to match
the constructed speech waveform to the original speech waveform as
closely as possible. The mean square error between the two speech
waveforms is continuously fed back into the system to perform a closed
loop optimization search of the excitation codebook.
5. Adaptive Post-Filtering of the Synthesized Speech
This filter is used in the decoder as a postprocessing step to further
improve the quality of the synthesized speech.
For more detailed information on LD-CELP and CELP, please refer to
[1] and [3].
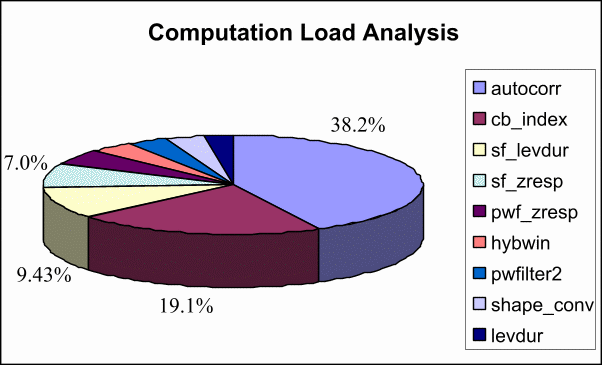
These figures were used along with an examination of the code
structure to select functions for vectorization on the VIRAM
architecture. We selected six functions, giving preference to (1) the
most computationally intensive functions, (2) the most parallelizable
functions, and (3) those functions having code structures different
from those already vectorized and which might be expected to use
VIRAM's vector features differently. Five of the selected functions -
autocorr, cb_index, levdur (including sf_levdur, which
is essentially the same algorithm), sf_zresp, and
pwf_zresp - are the five most computationally intensive
functions according to Quantify. Autocorr and
cb_indexed were initially expected to be highly vectorizable,
while levdur, sf_zresp, and pwf_zresp were
expected to have somewhat larger serial components. The
shape_conv function was selected because it appeared to be the
most vectorizable function in the LDCELP algorithm.
Many of the other functions used by the encoder are at least partially
vectorizable, but were not vectorized because of stringent time
constraints. Most of these functions either have code structure
similar to one of the vectorized functions, or are not computationally
intensive, or satify both of these criteria. All of the vectorized
functions except for cb_index and shape_conv are also
used by the decoder. While the decoder is on average slightly less
computationally intensive than the encoder [1], the postfilter
accounts for a significant fraction of the decoding computation. While
portions of many of the decoder-specific functions appear to be
vectorizable, these functions were not vectorized due to time
constraints. We decided to focus on the encoder alone in order to
produce a more complete vectorization and analysis of a single
benchmark.
The proposed VIRAM architecture supports variable virtual processor (VP) widths and supports both floating-point and fixed-point operations. Both floating-point and fixed-point implementations of LD-CELP exist; implementations designed for specialized DSP chips generally use the 16-bit fixed-point format to make more efficient use of the limited processor and memory performance on such systems. In our implementation, we used 32-bit floating-point exclusively in all of the vectorized functions, in order to maintain consistency with the compiled C components. This prevented differences in output which would result from rounding 16-bit fixed-point values and facilitated exact verification of the output with the original C implementation. The 16-bit fixed-point format would effectively double the number of lanes; the effect of increasing the number of lanes on overall performance is discussed in Section V. The VIRAM simulator also allows the maximum vector length (MVL) and the number of lanes to be fixed at runtime. We used an MVL of 64 (defined for a VP width of 64 bits), corresponding to a vector register length of 4096 bits. While an MVL of 32 would be more typical of a compact VIRAM implementation, the MVL of 64 allowed us to perform operations on vectors containing up to 128 32-bit values and implement all loops without strip-mining. (We decided that strip-mining, while adding to the complexity of the code, would not make a meaningful contribution to our analysis in the absence of highly precise simulation tools). We assumed 4 64-bit lanes (8 32-bit lanes) in our perfomance analysis.
Here is a brief description of the functions that were vectorized and
their vector implementations. We have included links to the C and
VIRAM source code.
1. autocorr:
This function computes the autocorrelation of a vector and is used to
update coefficients for the synthesis filter, gain filter, and
perceptual weighting filter. The function consists of two nested
loops; the inner loop is an inner product (multiply-add) loop. This
function is invoked from several different points in the program with
different problem sizes; the largest invocation has dimensions of 50
and 35 iterations for the outer and inner loops, respectively. Both
loops are vectorizable; we chose to vectorize the outer loop since it
allows longer vectors to be used and produces the output array with
very few scalar operations, resulting in better performance. This is a
very processor-intensive function; the only memory accesses are to
load the input array and to save the output array. Several VIRAM
features prove to be useful even for such a very simple function. The
autocorrelation function computes the inner product of different parts
of the same array; vector-vector extract (vext.vv) is used to access
subsegments of the vector register containing the array, greatly
reducing the number of memory accesses. A strided vector store (vlds)
with stride -1 is used to store the result to memory, since the
vectorized algorithm produces the output array in reverse
order.
2. cb_index:
This function searches the codebook to find the best codeword to
represent an input vector of 5 samples. LD-CELP uses a fixed codebook
of 1024 codewords. To reduce the computational complexity of codebook
search, the codebook is divided into two separate units, one
containing 128 signal shape vectors and one containing 8 gain levels.
The scalar implementation computes the correlation of the filtered
input signal with each shape codeword and estimates the optimal gain
level (with each codeword) by thresholding the correlation values. It
then computes the distortion for each shape codeword and returns the
index of the codeword with the minimum distortion.
Most of codebook search search consists of 128 independent
computations. Our vector implementation searches the codebook in
parallel, with each VP performing the computations corresponding to
one of the shape codewords. Stride 5 vector loads (vlds) are used to
load the shape codebook from memory. It is possible to load the shape
codebook into five of the 32 vector registers during initialization
and thus avoid loading it from memory every time cb_index is
called. However, we chose not to do this since our purpose is to
perform a performance analysis which is more widely applicable to
VIRAM systems with a range of system parameters, rather than one which
assumes an adequate number of large vector registers which are not
needed for other purposes. Vector comparisons and masked conditional
vector additions are used to select the optimal gain levels. Indexed
loads are used in the distortion calculation to retrieve energy
parameters for each shape codeword, using the selected gain level as
the index.
The minimum-finding computation is inherently serial. However, it is
possible to find the minimum element of a vector of length n in
log2(n) time. We place the first 64 elements of the distortion vector
in one vector register and the remaining 64 elements in another vector
register and find the element-by-element minimum of the two
halves. Recursively repeating this process eventually produces a
single minimum value: first we compute a 64-element vector containing
the minimum of all elements with index (i mod 64), then a 32-element
vector containing the minimum of all elements with index (i mod 32),
and so forth. This technique relies on the vector-vector extract
(vext.vv) instruction and can be used for many other inherently serial
calculations such as finding the maximum element in a vector and
finding the sum of the elements in a vector (often useful for
computing inner products).
3. levdur:
This function implements the Levinson-Durbin recursion algorithm and
is called by the synthesis, gain, and perceptual weighting filters. It
iteratively updates an array of linear prediction coefficients and
consists of a recursive outer loop and two vectorizable inner
loops. The first inner loop computes an inner product. The second
inner loop updates the coefficient array and has the form C_new(x) =
C_old(x) + a * C_old(b-x) where C_new and C_old denote the new and old
values of the coefficient array and a,b are constants. In our vector
implementation, we store C_old in memory and load it in reverse order
(stride -1) to obtain C_old(b-x). If memory bandwidth is limited, it
may be more efficient to maintain two copies of the coefficient array
in two vector registers, one in forward order and one in reverse
order. We could then update the forward copy by extracting part of the
reverse copy and adding it to the forward copy (at a different
starting position), and vice versa. This can be implemented using the
vector-vector insert (vins.vv) and vector-vector extract (vext.vv)
instructions. While this approach avoids memory accesses within the
outer loop, it also introduces additional overhead; thus it is unclear
if it would improve performance. The vector implementation of this
function includes a large proportion of scalar instructions,
necessitated by the relatively complex control structure which
includes a recursive outer loop and inner loops with variable
iteration counts.
4. shape_conv:
This function performs a convolution which computes the energy of each
filtered shape codeword. The computations for each of the 128 shape
codewords are mutually independent. This function is essentially 100%
vectorizable.
5. sf_zresp:
This function implements part of the synthesis filter. It contains
nested loops with iteration counts 5 and 50, respectively for the
outer and inner loops. Our implementation vectorized the inner loop. A
recursive vector technique was used to compute the sum of the elements
in an array, as was done in the minimum-finding part of
cb_index.
6. pwf_zresp:
This function implements part of the perceptual weighting filter. It
contains a recursive outer loop and two vectorizable inner loops. The
inner loops were vectorized.
Due to the large size of the instruction trace files, obtaining a complete trace of the program running on the entire test data set was not feasible. We empirically determined that the number of instructions executed per codeword generated generally varies very slightly from one iteration to the next (much less than 1%), except for the first 40 codeword cycles, during which the cycle counts for both the scalar and vector implementations are as much as 5-15% less than those for the later codeword cycles. This is most likely related to initialization procedures involving LD-CELP filters and the fact that the samples in the test data set corresponding to the first 14 codewords are zero vectors. To obtain accurate performance estimates, we obtained a trace of execution up to the 140th codeword and a trace of execution up to the 60th codeword. By subtracting the 60-codeword cycle and instruction counts from the corresponding 140-codeword counts, we computed cycle and instruction count statistics for an 80-codeword window extending from the 61st to the 140th codewords. This window corresponds to 400 input samples or 50 ms of real-time speech.
Due to a bug in the tracing software, we were unable to obtain a trace of the vectorized version of levdur. (The tracer erroneously traced instructions for other functions after the first several iterations of levdur). The original scalar implementations of levdur and sf_levdur were used for all of our performance measurements except for the rows in the tables labeled "levdur". We attempted to derive rough estimates for the instruction count and speedup for the vectorized version of levdur (levdurv) by computing the number of times each loop in levdurv is executed during the 80-codeword window and counting the instructions executed by one iteration of each loop. Assuming that each non-unit-time vector instruction requires on average 2-3 cycles (vector lengths averaging 14-26 were common), we estimated that levdurv executed about 240,000 instructions and achieved a speedup of about 1.5. The speedup may be greater depending on the degree to which scalar instructions could overlap with vector instructions.
| Function | Cycle Count (scalar) | Cycle Count (vector) | Vectorization Speedup |
|---|---|---|---|
| autocorr | 636,320 | 52,660 | 12.08 |
| cb_index | 593,779 | 61,393 | 9.67 | shape_conv | 123,060 | 11,580 | 10.63 |
| sf_zresp | 103,680 | 31,900 | 3.25 |
| pwf_zresp | 84,480 | 17,120 | 4.93 |
| all of above | 1,541,319 | 174,653 | 8.83 |
| levdur | 355,100 | 240,000 (est) | 1.5 (est) |
| all functions | 2,249,842 | 882,956 | 2.55 |
Table 1 shows the instruction counts measured for the scalar and vector versions of LD-CELP and the vectorization speedup. The autocorr, cb_index, and shape_conv functions were the most vectorizable and achieved the greatest speedups, as expected. The ideal speedup is 16 for vector arithmetic instructions and 8 for vector memory instructions (possibly higher due to instruction overlap). The measured speedup is affected not only by the vectorizability of the code, but also by the expressiveness and features of the VIRAM ISA, as well as the quality of the compiler optimization on a particular piece of code relative to the quality of handwritten assembly code. Thus the measured speedups are somewhat lower than the naive ideal figures, even for shape_conv, which is almost perfectly vectorizable. The speedup for cb_index is slightly lower than for shape_conv, since the minimum-finding computation has an inherent serial component. Autocorr has the largest speedup of all the vectorized functions, despite having a larger serial component than cb_index or shape_conv. This is most likely a result of the much smaller fraction of vector memory instructions in autocorr, as well as VIRAM ISA features which allowed us to write code that is more optimal than the code compiled from the C function. The filters sf_zresp and pwf_zresp achieve much smaller speedups because they have relatively small ratios of vector to scalar instructions. The vector lengths for these functions are also smaller, especially for pwf_zresp, which uses a vector length of 10. Both of these functions involve finding the sum of the elements of a vector register, and pwf_zresp has a recursive outer loop. The poor estimated speedup achieved by levdur is explained by the relatively complex control structure, large proportion of scalar instructions, and the need to store a vector register to memory and reload it in reverse order in the second inner loop. In general, the measured performance of the vectorized functions is quite well predicted by the structure of the code and the characteristics of the VIRAM ISA.
As shown in Table 1, the five vectorized functions listed achieve a large speedup of 8.83 because the two most computationally intensive functions, autocorr and cb_index, are both highly vectorizable. The overall speedup for the entire LD-CELP algorithm is much smaller. The five listed functions account for 68.5% of the scalar computation as measured by vsimp; levdur accounts for an additional 15.8%. Of the other 15.7% of the scalar computation, roughly 40% is contained within two functions, of which one is very vectorizable and the other is about as vectorizable as sf_zresp or pwf_zresp. The remaining functions each comprise much less than 2% of the scalar computation and exhibit a variety of structures: some are vectorizable but infrequently invoked; others contain nested loops with iteration counts of 5 or fewer and therefore are only slightly vectorizable; still others contain recursive serial components. A VIRAM implementation in which all vectorization is attempted whenever possible is likely to achieve a measured speedup of at least 3 and possibly approaching 3.5, but overall speedups approaching 4 are unlikely. A previous analysis cited by Rabaey [6] concluded that the LD-CELP algorithm is 79% vectorizable. The theoretical maximum speedup is 3.24 with 8 lanes and 3.86 with 16 lanes. Alternatively, the cycle count with 68% of the computation vectorized is 39% of the cycle count for the scalar computation, as compared to 26% for the ideal vector implementation with 16 lanes. Thus our partial vectorization achieves a majority of the potential speedup, and an optimally vectorized VIRAM implementation of LD-CELP is likely to come reasonably close to achieving the ideal vector performance.
Table 2 shows the total instruction count for the scalar and vector versions of each of the vectorized functions, and an estimate of the vectorizability of each function. We estimate the vectorizability of a function to be (1-vi/si) where vi and si denote the total instruction count for the vector and scalar versions respectively. Note that this vectorizability measure is specific to the VIRAM ISA and to the specific cases on which the functions are invoked. For functions such as autocorr, the vectorizability is based on the specific problem sizes on which autocorr is used and not on the autocorrelation algorithm in general. While not an absolute measure of vectorizability, this measure does provide a useful characterization of the code structure, and is closely correlated with the vectorization speedup as shown in Table 1. As expected, shape_conv is by this measure the most vectorizable, followed closely by cb_index and autocorr; the sf_zresp and pwf_zresp filters are substantially less vectorizable, and at least half of the levdur computation is serial.
| Function | Instruction Count (scalar) | Instruction Count (vector) | Percent Vectorizability |
|---|---|---|---|
| autocorr | 636,320 | 33,240 | 94.78% |
| cb_index | 593,779 | 12,562 | 97.88% | shape_conv | 123,060 | 1,160 | 99.06% |
| sf_zresp | 103,680 | 25,520 | 75.39% |
| pwf_zresp | 84,480 | 16,560 | 80.40% |
| all of above | 1,541,319 | 89,024 | 94.22% |
| levdur | 355,100 | 217,840(est) | 39%(est) |
Table 3 shows, for each function, the percentage of instructions in
the scalar version which are loads and stores, as well as the
percentage of vector instructions in the vector version which access
memory. The figures for the vector version do not count scalar
instructions and do not take into account the number of cycles
required for each vector instruction, and thus can only be used as
rough estimates of the prevalence of memory accesses. Nevertheless,
the scalar implementations are clearly much more memory intensive than
the vectorized versions. This is because the VIRAM vector architecture
has far more register space than a scalar architecture: the 32
4096-bit vector registers have a combined 16KB of data storage, as
much as the first-level cache in some processors. The vector
registers act as a cache, storing many repeatedly accessed data values
which would otherwise have to be loaded from memory. In the vectorized
version of autocorr, all of the required data is kept in
vector registers, eliminating the need for memory access except at the
very beginning and end of the function. The cb_index and
shape_conv functions are more memory intensive because
they must load the entire shape codebook (2560 bytes) from memory once
each time they are called. The huge memory bandwidth provided by
VIRAM's numerous memory banks is useful in these functions since the a
large portion of the shape codebook must be loaded before any of the
arithmetic vector computations can be performed. Loads and stores
generally used strides of 1, 5, or -1, all of which were able to take
full advantage of the high memory bandwidth provided by multiple
banks. The VIRAM architecture, in which DRAM and processing units are
located on the same chip, also has much lower memory latency, though
none of the simulation tools available to us are designed to measure
this effect. In general, memory bandwidth is much less of a limiting
factor for the vectorized implementation than for the scalar
version. Most of our vectorized functions are overwhemingly CPU-bound,
leaving VIRAM's vaunted memory capabilities largely underutilized.
| Function | % Mem Inst.(scalar) | % Mem Inst.(vector) |
|---|---|---|
| autocorr | 35.10% | 1.47% |
| cb_index | 14.18% | 8.25% | shape_conv | 22.90% | 13.95% |
| sf_zresp | 47.84% | 2.67% |
| pwf_zresp | 50.19% | 5.97% |
| all of above | 27.75% | 4.11% |
To demonstrate the relationship between additional vector hardware and
expected performance, Table 4 shows the approximate overall speedup as
the number of 32-bit vector lanes is increased from 1 to 32. These
figures were obtained from the crude vector and scalar cycle counts
produced by vsim (not vsimp) and use the
vectorized version of levdur. The vsim
cycle counts are less accurate than those reported by
vsimp and their absolute values should not be taken
seriously. The vector portion of the computation shows almost linear
speedup up to 4 lanes, with diminishing returns as the number of lanes
increases, especially with more than 8 lanes. The overall speedup from
8 to 16 to 32 lanes is nontrivial but not large, and must be weighed
against the cost of additional vector hardware for extra lanes. Given
the inherently limited parallelism in LD-CELP, we believe that 4 to 8
lanes represents a reasonable tradeoff.
| Number of Lanes | Cycle Count | Speedup |
|---|---|---|
| Scalar | 167.960M | 1.00 |
| 2 | 98.813M | 1.70 | 4 | 75.268M | 2.23 |
| 8 | 63.756M | 2.63M |
| 16 | 57.949M | 2.89 |
| 32 | 55.235M | 3.04 |
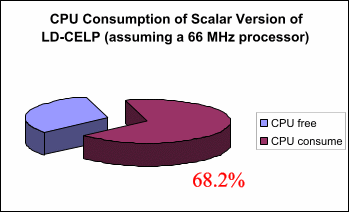
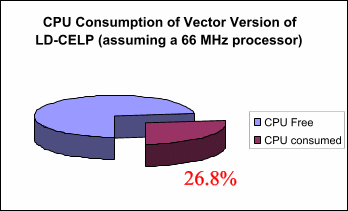
Finally, we performed some simple approximate calculations to
determine the real-time requirements of the LD-CELP algorithm for both
the scalar and vector implementations. Figures 4 and 5 show the
estimated CPU utilization when running the LD-CELP encoder in real
time for the scalar and vector versions, respectively, assuming a
processor clock speed of 66 Mhz. We also benchmarked the performance
of our vector code against figures obtained using a TMS320C30 DSP
system [3]. The TMS320C30 performed real-time LD-CELP encoding of
speech sampled at 8 kHz, utilizing approximately 90% of the available
processor cycles. Since the TMS used in that study had a CPU clock
speed of 33 MHz, the encoding of one second of real-time speech
consumed 29.7 million clock cycles. By comparison, the same
computation consumed 45.0 million cycles for our scalar implementation
and 17.7 million cycles for our vector implementation (these figures
are derived from the figures in Table 1. These figures suggest that
the TMS is significantly faster than our scalar implementation but
substantially slower than our vector implementation. The performance
advantage of the TMS over our scalar code can be explained by the use
of optimized hardware to support single-cycle multiply-accumulate in
standard DSP chips. The faster performance of our vector code relative
to TMS is most likely a function of VIRAM's extensive support for
vector operations which can perform many more computations per cycle
than a scalar DSP. Since the vector code could be made to run even
faster by vectorizing all parallel code segments and using a 16-bit
fixed-point format, these figures very likely underestimate the
performance of our vector program. This benchmarking comparison is
rather crude, as a fair and accurate comparison of such contrasting
architectures is very difficult to obtain. The only data we could
obtain for the TMS DSP is several years old; and while we compare
cycle counts rather than execution times, architectures are constantly
evolving over time. A meaningful comparison would also need to
compare the clock speeds which can be achieved by the two
architectures given current technologies, as well as the relative cost
of the systems being compared. While the cost of the VIRAM chip is
unclear, we would expect that the TMS DSP chip would cost much less,
while the VIRAM chip would be suited to a wider range of complex
vectorizable algorithms.
 |
 |
Our vector implementation took advantage of many of VIRAM's ISA
features. The ability to set the virtual processor width at runtime is
useful because it allows us to maximize the number of lanes based on
the data size and precision required. As mentioned previously, VIRAM's
fixed point instructions could be used with a 16-bit VP width (as is
commonly done in DSP implementations) to double the number of lanes
and improve performance. Table 4 shows that with 8 or 16 32-bit lanes,
this could increase the speedup by as much as 0.20, depending on any
changes in the instruction count which may result from translating the
program to fixed point. Vectorized LD-CELP made extensive use of
vector memory access features, including variable stride and negative
stride loads and stores and indexed loads. Also frequently used were
vector manipulation features, including vector insert and extract
instructions; it was also common for functions to vary the vector
length iteratively or repeatedly during loops and other
calculations. While vector comparisons and conditional operations were
commonly used, none of the functions we vectorized used vector mask
arithmetic. As we have seen, LD-CELP does not conform to the
stereotype of the simple multiply-accumulate DSP algorithm exemplified
by the convolution; our vectorization has made extensive use of a
substantial subset of the VIRAM ISA.
Our results also suggest that vector architectures can substantially
improve the performance of many DSP applications. An accurate
quantitative comparison of VIRAM with existing DSP chips would need to
examine the costs of the currently competing technologies, as well as
the effects of various architectural design decisions on clock cycle
time and instruction count; such an exhaustive study is beyond the
scope of this investigation. However, there is strong evidence to
support the conclusion that VIRAM, with its extensive vector
processing and memory access capabilities, can achieve substantially
better performance on LD-CELP than standard DSP implementations which
are predominantly of a scalar design. While other simpler and more
vectorizable DSP applications would probably use a smaller subset of
VIRAM's vector features, they are also likely to achieve greater
vectorization speedup than LD-CELP. As improving hardware technologies
allow ever-increasing numbers of transistors to be placed on a single
chip, the possibility of incorporating support for vector computation
on DSP systems merits serious consideration.
[1] J.H. Chen, R.V. Cox, Y.C. Lin, N. Jayant, M.J. Melchner 'A Low-Delay CELP coder for CCITT 16 kb/s Speech Coding Standard' in IEEE Journal on Selected Areas in Communications, Vol 10, June 1992.
[2] Z. Kostic, S. Seetharaman, 'Digital Signal Processors in Cellular Radio Communications' in IEEE Communications, December 1997.
[3] G. Hui, W. Tian, W. Ni, D. Wang, 'Real-Time Implementation of 16 kb/s Low-Delay CELP Speech Coding Algorithm on TMS320C30' in IEEE Tencon, 1993/ Beijing.
[4] J.H. Chen, M.J. Melchner, R.V. Cox, D.O.Bowker, 'Real-Time Implementation and Performance of a 16 kb/s Low-Delay CELP Speech Coder' in IEEE Communications, 1990.
[5] Intel MMX Application Notes for Speech Coding.
[6] Personal communication, Prof. J. Rabaey, EECS Dept, UC Berkeley.
[7] The Berkeley Intelligent RAM (IRAM) Homepage
[8] Source downloads